 Michael Shafer
Michael Shafer
Create an RSS feed from any website using Apify
RSS is a great way to watch for interesting content on the Internet. I skim through a whole range of website feeds in Feedly, then any articles I actually want to read I save to Pocket for later. Sometimes, though, websites don’t have an RSS feed, or the RSS feeds they have are too broad or too narrow.
In these cases I use Apify to regularly crawl the website and create my own RSS feed. It’s awesome! You have complete flexibility over what content to include in the feed. Apify has a free Developer tier that gives you plenty of capacity to scrape a few websites every day. They actually have an existing blog post on this topic, but below I’ve added some extra things you might need to get it working.
1 - Create the crawler on Apify
Sign up for an account on Apify and click Tasks > “Create a new task” > “Legacy PhantomJS Crawler”. This task type is the only one I’ve found that lets you access crawler results via RSS.
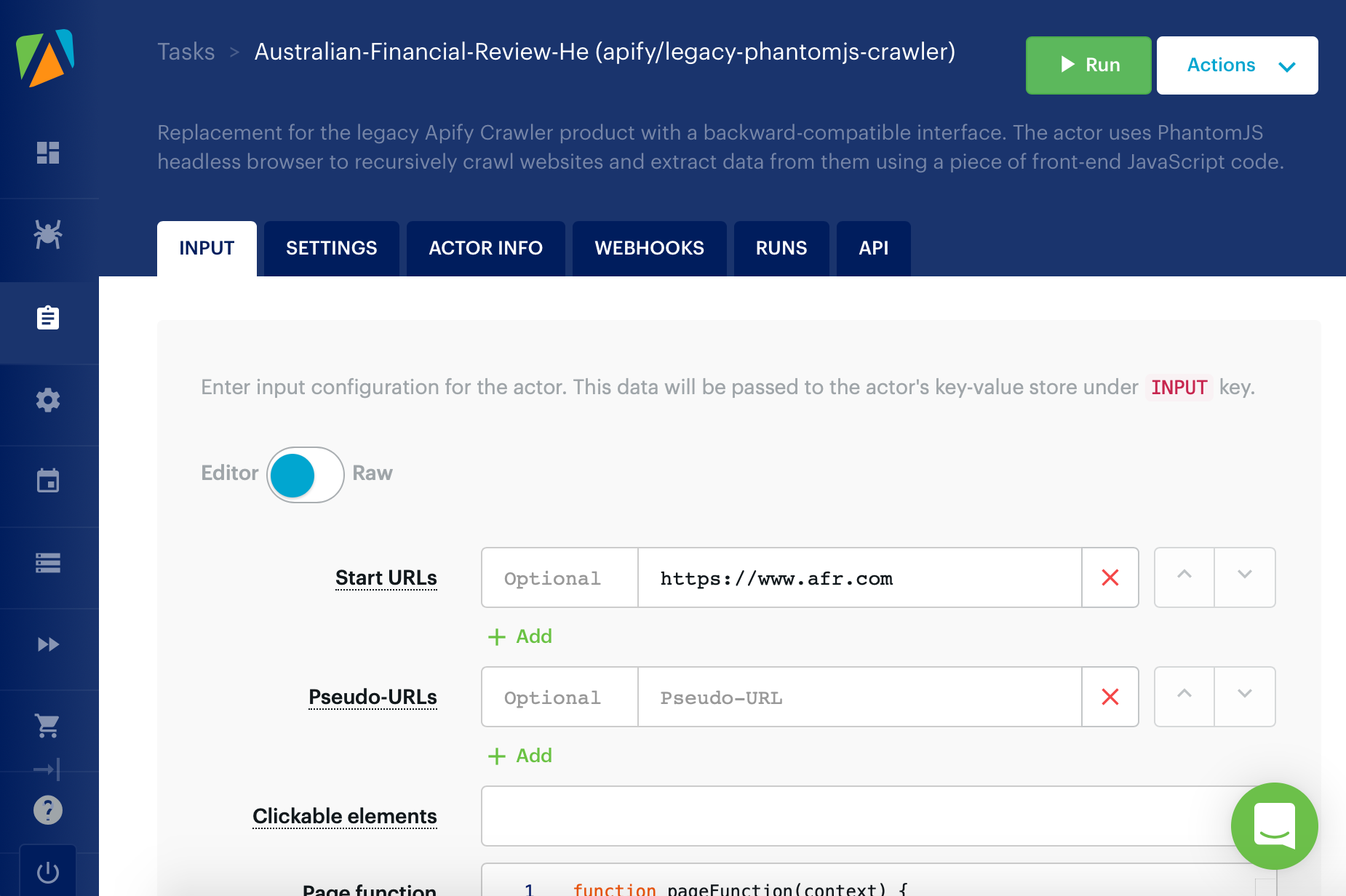 The crawler configuration page on Apify
The crawler configuration page on Apify
Set the “Start URLs” to the page you want to scrape, and make “Clickable elements” blank if you only want to scrape one page. You would use clickable elements if you wanted to jump from the starting page to other links found on the page.
2 - Create the page scraping function
Apify lets you write a simple JavaScript function to look for elements and return structured data about that page. In this case, we’re going to use jQuery to find the right elements, and we’ll return a list of JSON objects that each represent an RSS feed item.
Use your browser’s web inspector to look for specific HTML elements and CSS classes that will let you hone in on the headlines you want.
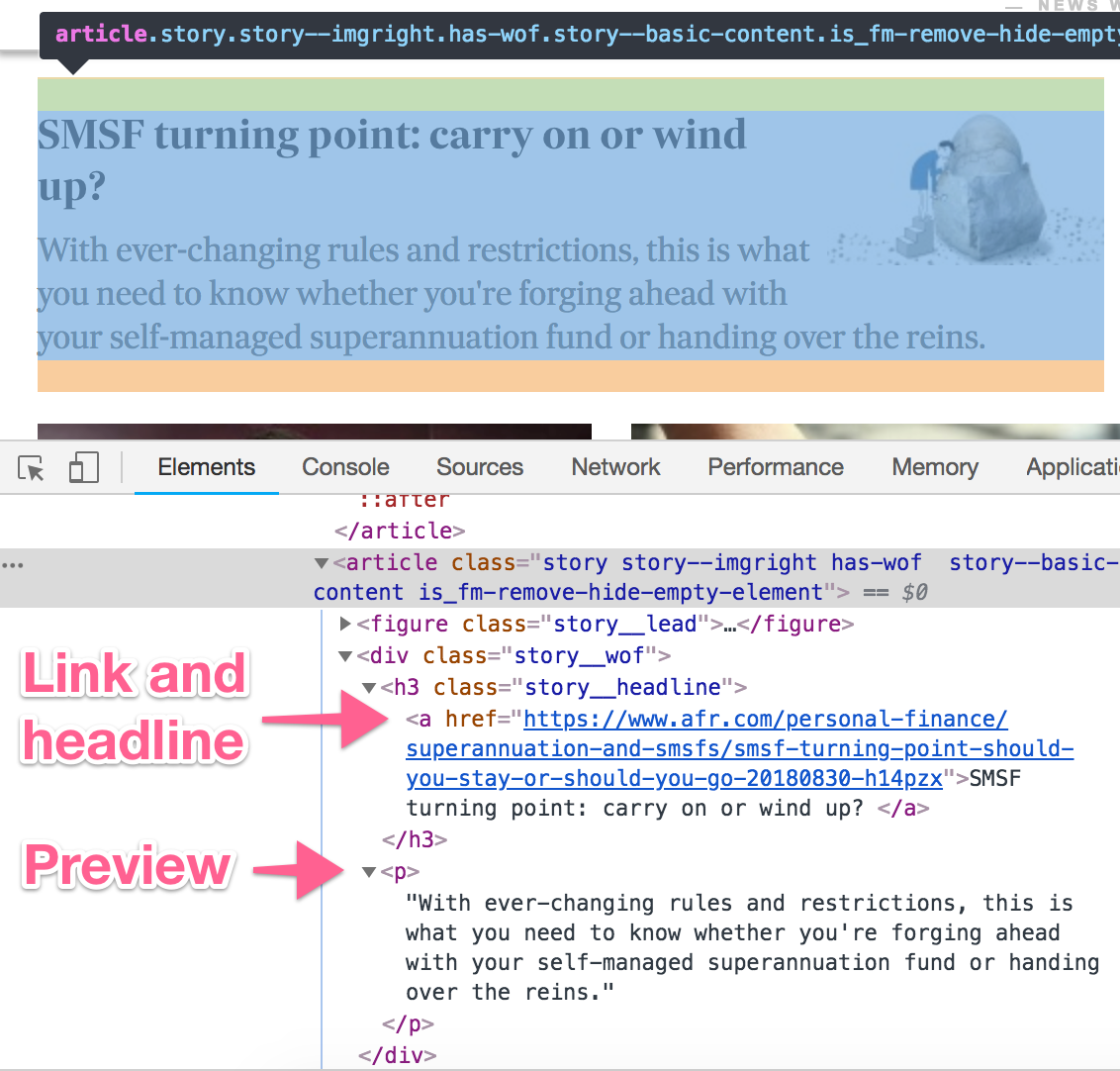 Inspecting HTML elements to scrape in Chrome Dev Tools
Inspecting HTML elements to scrape in Chrome Dev Tools
On this website I only want to look at one container div with CSS classes newswell-hero and section, and then within that I want to look at <article> elements with the CSS class story. For each article I find, I want to extract details about the <a> and <p> tags. We can achieve this using jQuery:
function pageFunction(context) {
var $ = context.jQuery;
var results = [];
$(".newswell-hero.section article.story").each(function() {
results.push({
title: $(this).find(".story__headline a").text().trim(),
link: $(this).find(".story__headline a").attr("href"),
guid: $(this).find(".story__headline a").attr("href"),
description: $(this).find(".story__wof > p").text()
});
});
return results;
}The keys we’re returning in each object will be converted to XML elements in the resulting RSS feed. One important one is guid — this uniquely identifies a particular article, and is used by feed aggregators, like Feedly, to determine whether a particular item is new.
If your website has more information available, you can add more properties to the feed—for example, you might want to add pubDate to indicate when the article was published. All of the available RSS elements can be found in the RSS 2.0 Specification.
3 - Test it
Click “Run” at the top of the screen and Apify will crawl the page and return your results.
Once your crawl has finished successfully, you should be able to see this screen:
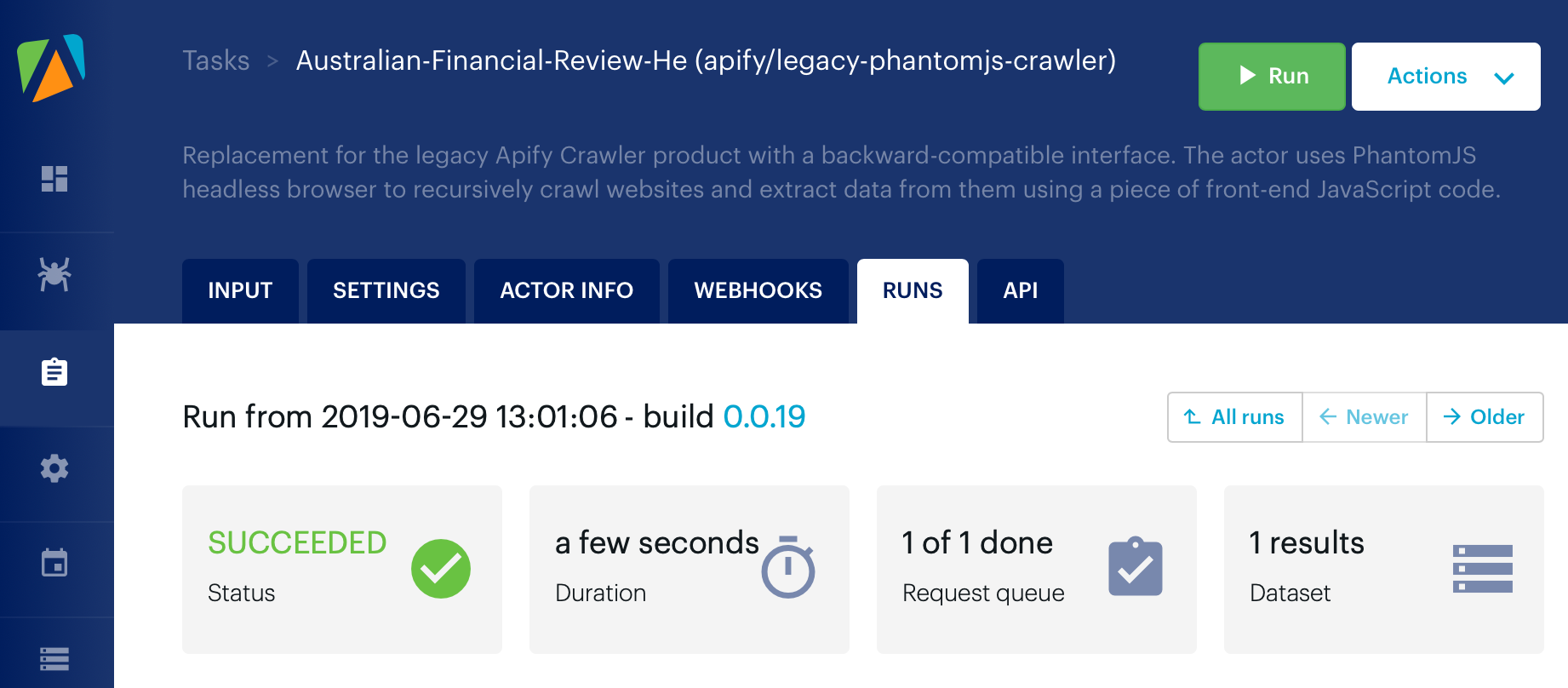 The status page of a successful run of the crawler
The status page of a successful run of the crawler
To view the data returned by the pageFunction, click on the “1 results” link to the right, then click the “Preview Data” button. You should see a table of results like this:
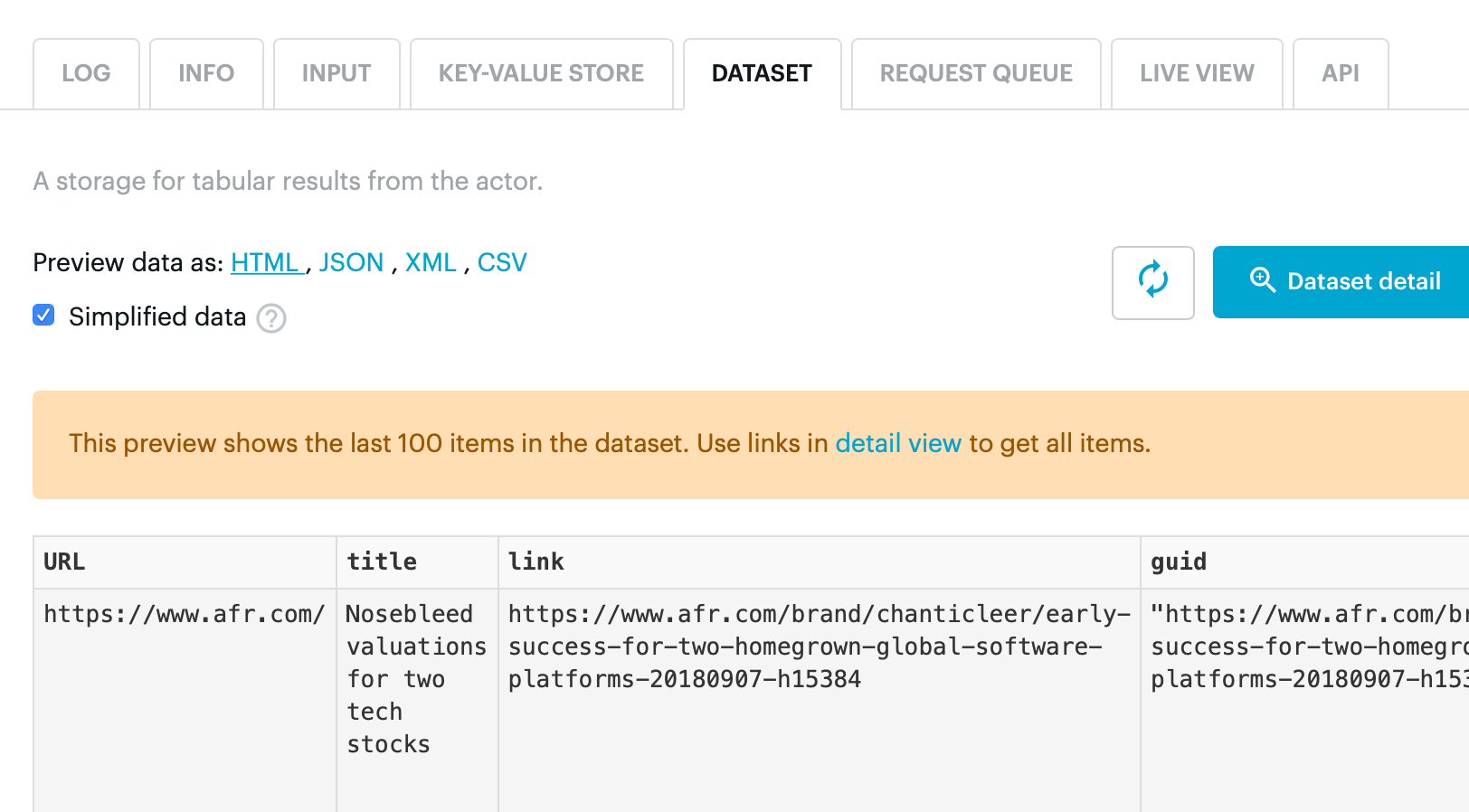 Previewing the data returned by our crawler
Previewing the data returned by our crawler
4 - Subscribe to your new RSS feed
To get the RSS feed URL, click the same “1 results” link as before and scroll down to the bottom where there should be a table of formats containing one row for “RSS”:
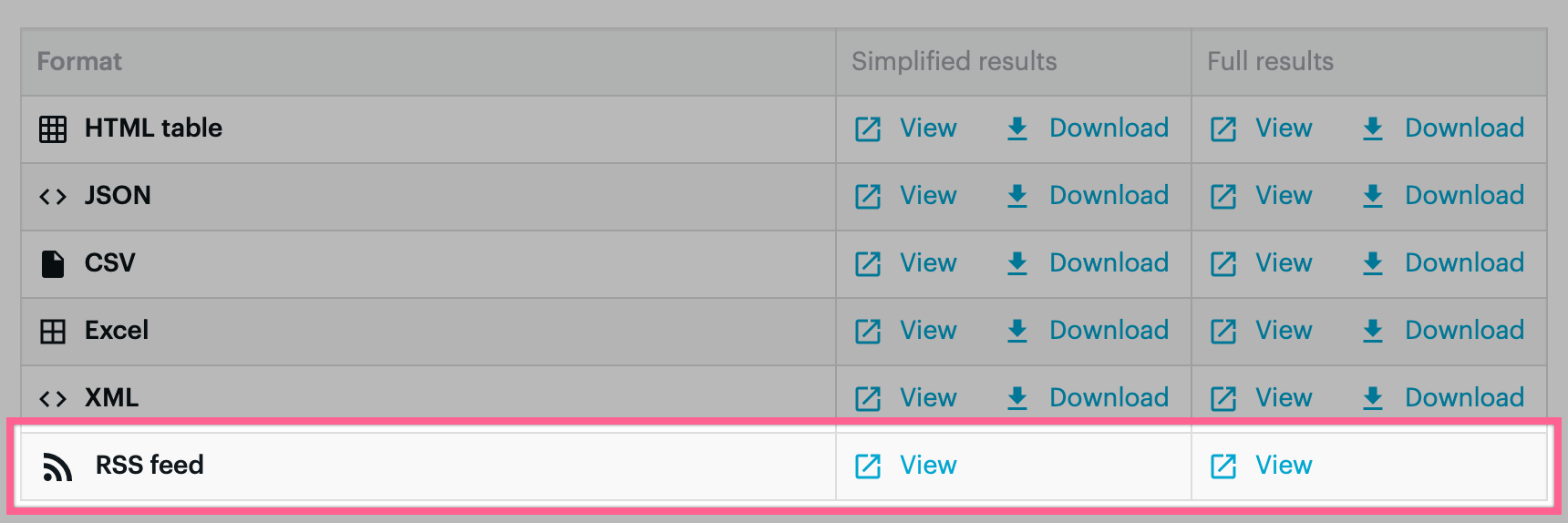 Output formats of our Apify crawler
Output formats of our Apify crawler
Copy either of the “View” links to your RSS reader and voilà, you should see a feed of your hand-picked articles:
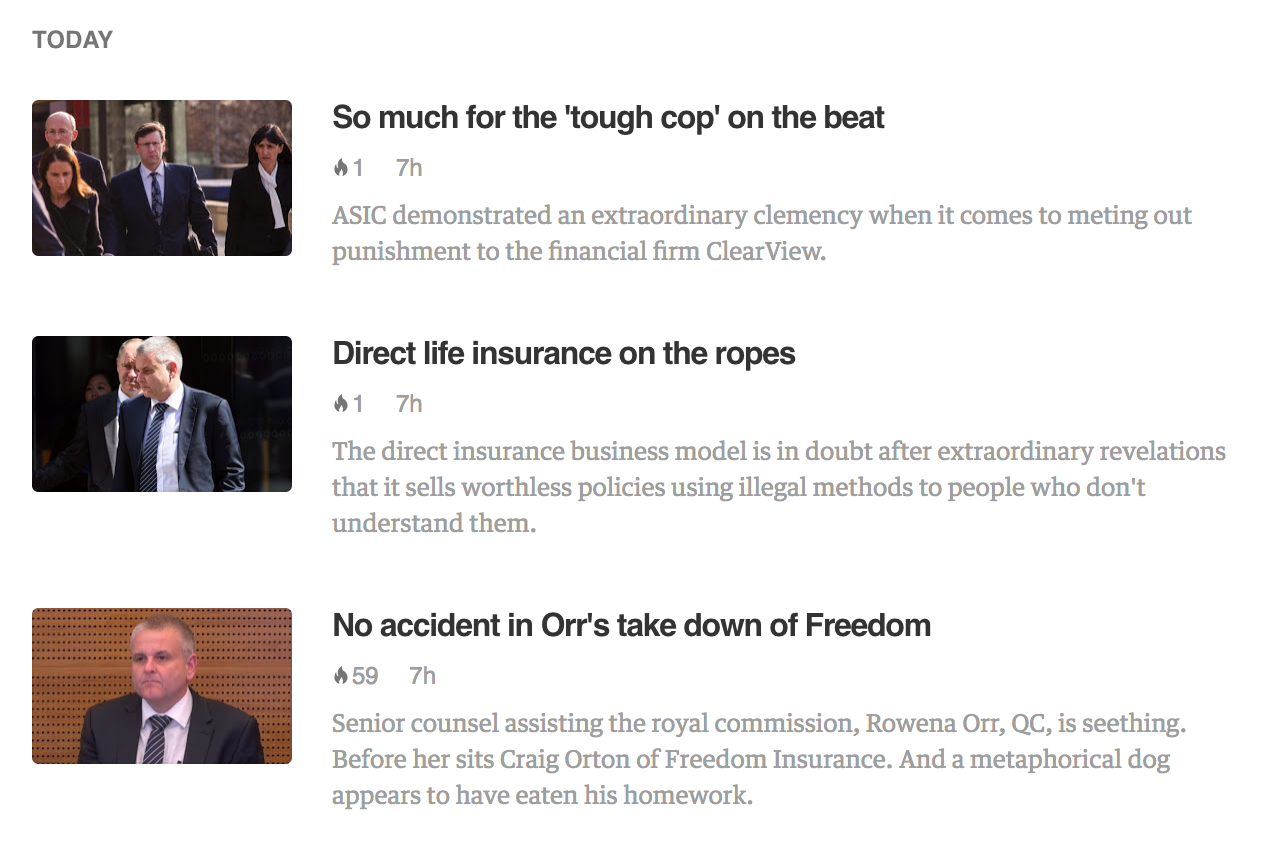 New items from the RSS feed appearing in Feedly
New items from the RSS feed appearing in Feedly
Subscribing using Feedly is extra handy because it often adds images for you automatically.
5 - Schedule it
We need to make sure the feed is updated with new articles as the website changes, and you can do this by adding a schedule in Apify from the “Actions” menu in the top right of the screen. I have a @daily schedule on mine because I only need the top headlines once a day.
Now you can sit back and watch the articles stream in to your RSS reader every day.